Color-Magnitude Diagrams
As discussed in Stellar Spectra, the surface temperature of a star has a direct correlation to its color, so we can use our understanding from Star Colors to represent decreasing temperature as increasing redness. Luminosity is more difficult to accurately represent, however, since in order to calculate an object’s luminosity you need to first know its distance from Earth. It represents the same physical property as the absolute magnitude, which is the amount of energy being released in a given amount of time. This can be extrapolated using the object’s apparent magnitude and distance, the latter of which can often only be learned by analyzing its parallax or using other methods which are beyond the scope of this activity. This is where star clusters become very useful to astronomers, since we know that all of the stars inside a single cluster are at almost exactly the same distance from Earth, in addition to having near-uniform age and chemical composition.
There are two primary classes of clusters, open and globular. An open cluster is a relatively young group of stars (between a million and a few billion years old) which has formed from a traveling cloud of dust when it entered the galactic disk. The strong gravitational field within the galaxy can compress such clouds into groups of stars which scatter slowly over time, resulting in a loose collection of stars. Due to the nature of their formation, most open clusters are found within the arms of the Milky Way.


Globular clusters are very old—on the order of ten billion years, which approaches the age of the universe itself. They are formed from much larger clouds of matter, producing many more stars with enough total mass that they become gravitationally bound to each other. They typically appear as a bright, dense ball of stars and are found chiefly in the halo of the Milky Way, near the central bulge but outside the plane of the disk.
Because of the way they formed, we know that stars in clusters are in the same small region of space, so we approximate that each one is at the exact same distance from Earth. Since absolute magnitude is simply the apparent magnitude when viewed from a standard distance, each star’s apparent magnitude will hence be offset from its absolute magnitude by some constant which is related to its actual distance. We can thus produce a color-magnitude diagram of the stars in the cluster and it will be representative of the same object’s HR diagram, merely offset on the y-axis.
Anatomy of a Diagram
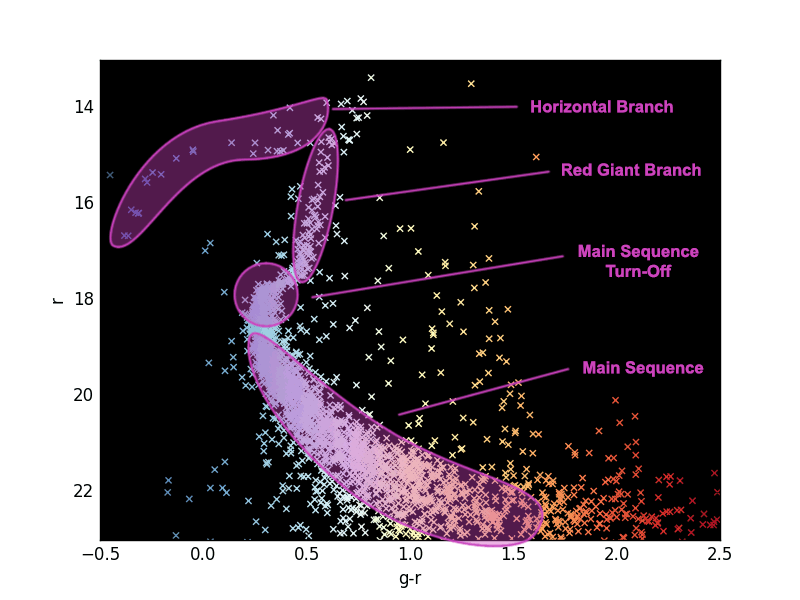
When stars first form, most of them lie on what is called the “main sequence,” the stripe of stars running diagonally from the lower-right toward the upper-left. Their exact position on the stripe is determined by their mass, with more massive stars sitting in the brighter, bluer area.
Once the most massive stars have burned through their hydrogen supply, they often evolve into red giants or supergiants, which stay at about the same luminosity but become redder. This produces the “red giant branch” as progressively less massive stars also run out of fuel; the corner or bend where the main sequence leads into the red giant branch is called the “main sequence turn-off,” or sometimes just the turn-off.
Some stars will continue from the red giant branch onto the “horizontal branch,” which reaches back toward the bluer and dimmer portion of the diagram.
Choosing an Object
The first, and very important, step is selecting a cluster with good photometric data. If you already have a favorite cluster, type it into the “name” box in Navigate and click “Resolve” to see if it’s in the SDSS database. If not, you can look at this catalog of open and globular clusters that have already been found with SDSS data and choose one that you like. When you’ve found an object, type its name into Navigate as just explained, and it will likely appear automatically. Some of the clusters aren’t listed in the SDSS index, however; if that’s the case, each object’s RA and Dec can be found by clicking on its image in the catalog. You can then type the values into Navigate by hand.
While selecting a cluster, don’t be afraid to look closely at several in order to compare your options and find the one best suited to your needs—not every cluster in the database will produce a good HR diagram. Ask yourself:
- What kinds of data do you need to build a Hertzsprung-Russell diagram?
- How many data points (stars) will be necessary to see a clear and distinct trend?
- Why do some clusters have better photometry than others? How will that affect your plot?


You may want to explore some of these questions further by gathering multiple sets of data from the same cluster, using different selection parameters, to better understand how the end result is influenced by this very first step. Additionally, it’s generally a good idea to document your work so that you can go back and repeat steps or make alterations as necessary. Keep a record of the search parameters you use and other choices you make during this activity so that you can more easily analyze the process afterward.
Collecting Data
When formulating your data request, it can be very helpful to take advantage of the tools offered by SDSS to streamline and optimize the collection process. Those who have little or no programming experience may find it easiest to dive in using the SDSS EZSearch Tool, which allows you to quickly and intuitively fill in your search parameters but allows for very little customization.
When formulating your data request, it can be very helpful to take advantage of the tools offered by SDSS to streamline and optimize the collection process. Those who have little or no programming experience may find it easiest to dive in using the SDSS EZSearch Tool, which allows you to quickly and intuitively fill in your search parameters but allows for very little customization.
If you’re familiar with programming syntax or willing to learn the basics, the SQL Search tool below is a more powerful tool which can offer versatility and complexity in areas where the Search Form is limiting. You can find a resource to get you started with your own SQL searches using this SQL Search tool – see the instructions below, or the SkyServer SQL Tutorial.
Search
Results will appear here
To start your query, think about exactly which data you’re looking for and what criteria you’ll use to select it. Much of the following choices are made for you in the Search Form, but if you explore the Schema Browser to better understand the options at your disposal through the SDSS database, you can come up with more creative solutions and make educated decisions about what goes into your diagram. While answering the questions below you will likely want to look through the View titled “PhotoObj,” which samples from the best photometric data available. In general, it may be a good idea to request more options than you think you’ll need, in case you change your mind later.
- Several magnitude-fitting models are available in PhotoObj: psfMag, fiberMag, petroMag, deVMag, expMag, modelMag, cModelMag, and dered. How do they differ? Which is best suited to the plot you’ll be making, where brightness and color are the two important variables?
- Of the five ugriz filters, you will need to use two in your plot. Which ones will you use? Refer to the “Color” section of Star Color if necessary.
- Should your data be limited to a certain magnitude range? What about magnitude error?
- What other criteria can you use to select more relevant and helpful data?
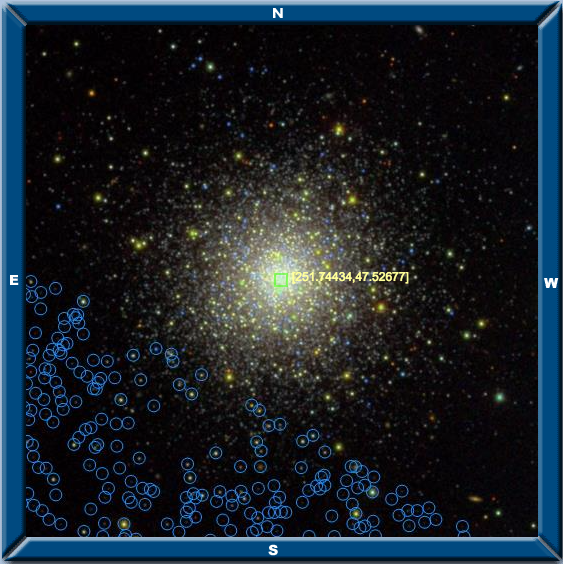
Once you have the structure of your search, a very important decision you still need to make is exactly which area of the sky to take data from. This can have a large impact on your final HR diagram, so it may be a good idea to pause and consider your options. You can hand-pick minimum and maximum RA and Dec values using Navigate in order to select a “rectangular” portion of the sky around your object, or you can use the SDSS fGetNearbyObjEq function to capture a circular zone around the center of the cluster. Either way, make sure to check the “Photometric objects” box in Navigate to estimate how many data points you’ll have for a given patch of sky. You can also apply the COUNT(*) function to see the exact number before making your request.
Choosing a good radius to select from is a balancing act, since if you stay close to the center there will be fewer data points—especially due to oversaturation—and it may be harder to see a trend. It’s essential to note that very few photometric data will appear in the center of any cluster, since the SDSS telescope was designed to see very dim objects, so bright bundles of stars overwhelm the CCD to make for bad data. As you expand your search, you will select more stars which are dim members of the cluster, but you will also capture some which are not part of the cluster and just happen to be in line with it from the telescope’s point of view. There is no hard-and-fast rule for this, but it can be helpful to request object counts for several sizes until you have an appropriate number of data points.
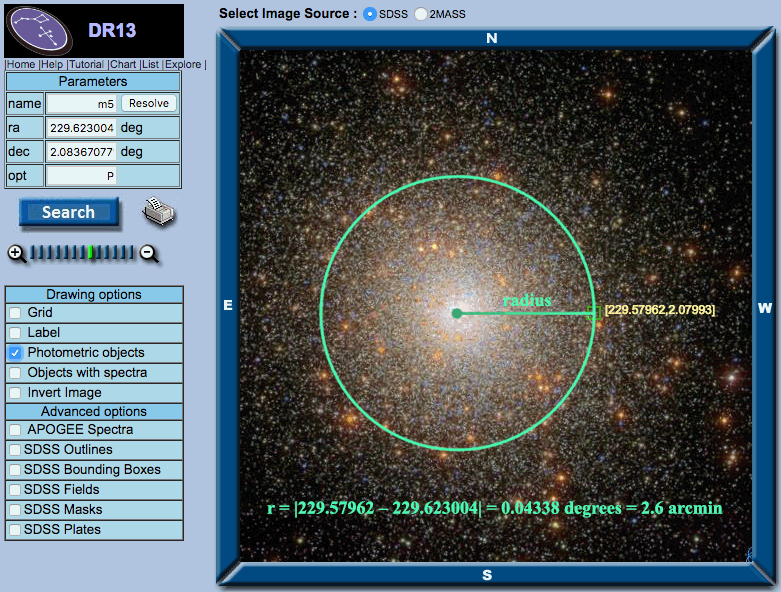
If you use the fGetNearbyObjEq, you can calculate the radius of your search by imagining a circle around the center of the object and selecting a point in Navigate on the circumference of the circle to get the RA and Dec. Make sure the point has the same RA or Dec as the center of the cluster, so that the radius of the circle will be the difference in the other coordinate. This number will be in degrees, however, and the equation takes radial inputs in arcminutes, so be sure to convert the unit first
Once you’ve acclimated yourself to using SQL and navigating the SDSS schema, those who are serious about using large amounts of data or saving their searches for later reference may want to create a free account with SciServer in order to use the CasJobs search tool.
When you’re satisfied with your query, output the results of your final request as a CSV file and save it to your hard drive.
Manipulating Data
Once you’ve downloaded your data as a .CSV file, you can import it into a spreadsheet editor to begin further analysis. You can upload your .CSV file and manipulate and plot the data within Google Sheets. You can also use your favorite spreadsheet editor, such as Excel, if you feel more comfortable there. Those looking for more control can even use Python to create their diagrams, with the help of its NumPy and MatPlotLib libraries.
Recall that a color-magnitude diagram is a plot of apparent magnitude on the y-axis and color on the x-axis, so we’ll choose the magnitude through one filter to be plotted against the color index, which is calculated using two filters. If you’re not sure how color calculations work, see the “Color” section of Star Color for an explanation. The exact process for performing calculations and plotting data will differ depending on the software you use, so refer to user manuals or other guides as needed.
You need to create a column of data representing color, given the magnitudes through the two filters you selected, and then choose one of the filters to represent your apparent magnitude. By convention, this is the longer wavelength, which is the one being subtracted in the color calculation.
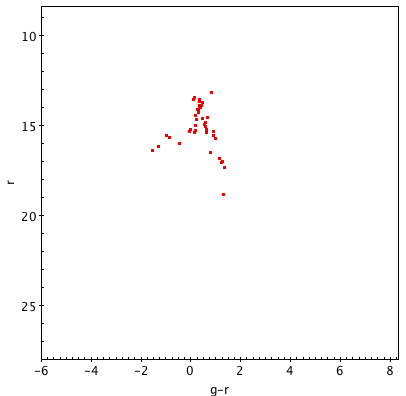
The image below shows three color-magnitude diagrams made from the same cluster, using different-sized searches. Pay attention to how the number of data points can affect your ability to find trends.
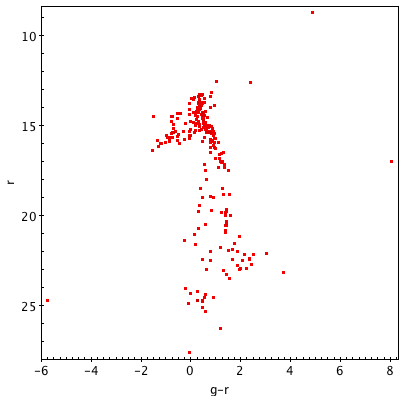
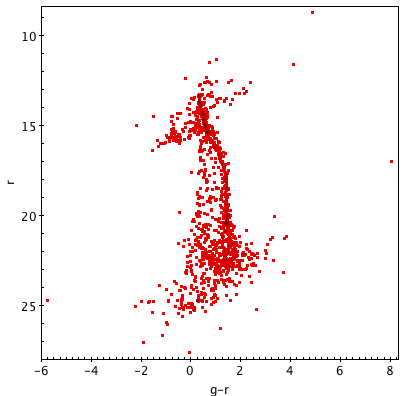
Reviewing Results
Our end goal is to produce a Hertzprung-Russell diagram, so make sure your axes are going in the right direction. You can check this intuitively by considering what the axes actually represent: luminosity is how much energy an object emits, so when luminosity increases, how should the apparent magnitude be affected? And since an HR diagram plots decreasing temperature on the x-axis, what does that imply about the color of light being emitted? Should it go from bluer stars to redder stars or the other way around?
A successful color-magnitude diagram can take many shapes. Your cluster may look very different from a typical HR diagram, especially since the SDSS telescope is limited in its range from about 14th to 24th magnitude. This means that you’re looking at a horizontal cross-section of the full cluster, so don’t be discouraged if all of its features aren’t visible; here are some sample clusters which may help you identify the prominent forms. Click each one to see it at original size.
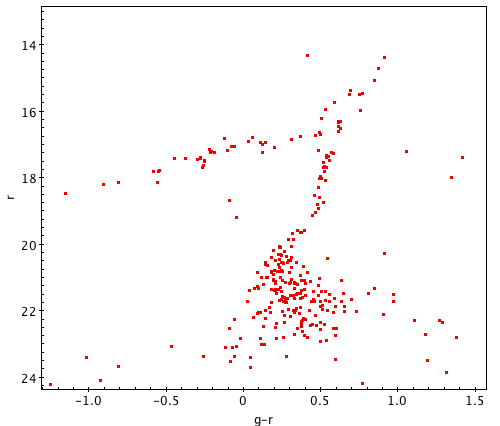
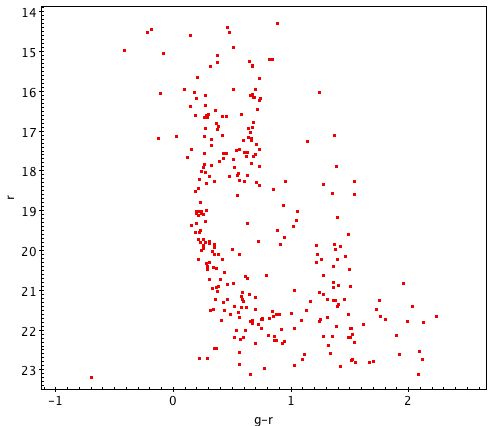
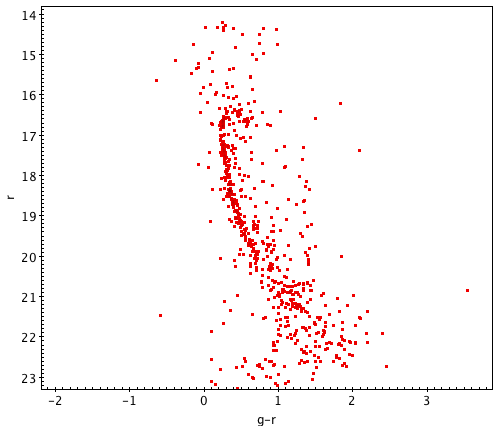
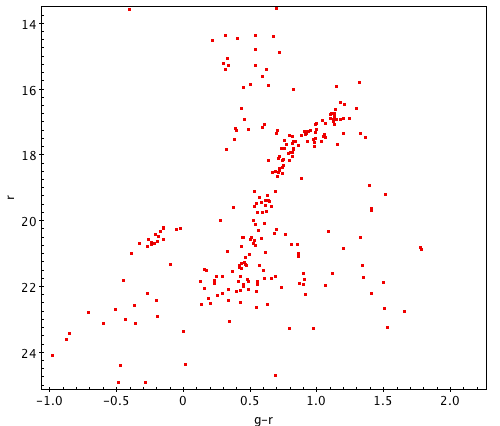
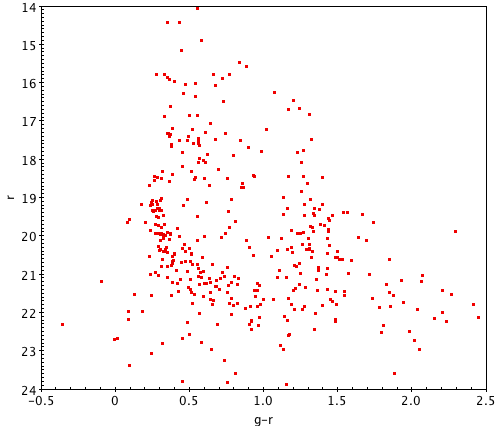
Before moving on, it’s important to review the process you’ve gone through and consider where things may have gone wrong. Somebody who’s very experienced with HR diagrams might be able to tell at a glance where experimental error and irrelevant data affected the results, but building that sort of intuition takes years of practice. Read through the activity again and look at any notes you may have taken to ask yourself:
- In which steps did you need to make subjective decisions about how to collect or manipulate the data? How could those choices have changed your final diagram?
- Do any steps exist that aren’t influenced by human decisions? For example, are there procedures that everybody must perform the same way?
- If you were to repeat this activity in the future, are there any things you would do differently? Why?
If you worked in a group, it may be helpful to compare your methods and results with others in order to look for trends. Discuss which things worked well and which didn’t.
You now have a color-magnitude diagram! Depending on the properties of the cluster and your methods in selecting data, each plot should look a little bit different. Hopefully you’ll be able to identify multiple features, such as the main sequence, turn-off, and red giant branch. The exact shape depends on the unique properties of your cluster; we’ll investigate that further in the third part of this Expedition, but first we have to scale the plot to absolute magnitudes using the Distance Modulus.